Was ist stabile Diffusion und wie kann man ihre Leistung maximieren?
Der Vormarsch der Künstlichen Intelligenz übernimmt mittlerweile einige Programme, die bei der Generierung von Bildern helfen sollen. Möglicherweise sehen Sie das Werkzeug „Stabile Diffusion“. Aber Was ist stabile Diffusion?? Dies ist ein Bildgenerierungstool. Sein Hauptzweck besteht darin, mithilfe von Eingabeaufforderungen Bilder zu generieren, und die Leute finden es ansprechend und unterhaltsam, verschiedene Charaktere und Elemente gemeinsam zu erstellen. Erfahren Sie mehr darüber, was stabile Diffusion ist und wie sie funktioniert.
Guide-Liste
Teil 1: Was ist stabile Diffusion? Teil 2: Was ist eine stabile VAE-Diffusion? Teil 3: Was ist Dreambooth bei Stable Diffusion und wie wird es installiert? Teil 4: Was ist die CFG-Skala bei stabiler Diffusion? Teil 5: Was ist Rauschunterdrückung bei stabiler Diffusion? Teil 6: Was ist Clip Skip Stable Diffusion und wie wird es verwendet? Teil 7: Was ist stabile Diffusionsgeschwindigkeit und wie beschleunigt man sie? Teil 8: FAQs zur stabilen DiffusionTeil 1: Was ist stabile Diffusion?
Es handelt sich um ein Deep-Learning-Text-zu-Bild-Modell, bei dem Bilder durch die Eingabe von Eingabeaufforderungen zur Beschreibung des Hauptthemas erstellt werden. Sie können beispielsweise „Katze“ eingeben und das Tool generiert ein Bild einer Katze. Bei der Eingabe komplexer Eingabeaufforderungen können jedoch weitere Details hervorgehoben oder hinzugefügt werden. Das generative neuronale Netzwerk wird zu mehr als einem KI-Werkzeug, da es auch mit anderen Aufgaben wie Outpainting, Inpainting und Bild-zu-Bild-Übersetzung über Texteingabeaufforderungen konditioniert wird.
Stable Diffusion wurde von der Stability AI entwickelt und finanziert, aber die CompVis-Gruppe an der Ludwig-Maximilians-Universität München verfügt über die technische Lizenz für das latente Diffusionsmodell. Darüber hinaus wurde die Entwicklung von den Forschern Patrick Esser und Robin Rombach geleitet, die als Unterstützer der Projekte weitere Trainingsdaten von gemeinnützigen Organisationen in Deutschland einholten. Später im Oktober 2022 sammelte das Unternehmen 101 Millionen US$, nachdem es erstmals im August 2022 eingeführt wurde.
Teil 2. Was ist VAE-stabile Diffusion?
Möglicherweise sind Sie bei der Verwendung des AI-Fotogenerators auf dieses Problem gestoßen, und VAE ist für das Tool hilfreich. VAE steht für Variable Auto Encoder und wird zur Feinabstimmung des Decoders verwendet, um bessere Details darzustellen. Es ist eine Ergänzung zum KI-Tool, da es dazu beitragen kann, schärfere Bilder und lebendige Farben zu erhalten und die Erstellung von Händen und Gesichtern zu verbessern.
Natürlich dient VAE mehr als nur der stabilen Diffusion, da alle Modelle über integrierte VAEs verfügen, um die Details zu ermitteln. Beim Vergleich handelt es sich um das Ergebnis zwischen den einzelnen Modellen und darum, wie sie aussehen, wenn Sie die Bilder komprimieren. Darüber hinaus gibt es separate VAE-Dateien, die Sie auf Ihr Gerät herunterladen können. Um einen Decoder auszuprobieren, können Sie Folgendes verwenden:
- Orangemix/irgendetwas VAE für Anime.
- Kl-f8-anime2 für Anime.
- Vae-ft-mse-840000-ema-beschnitten für Realismus oder Gemälde.

Teil 3. Was ist Dreambooth bei Stable Diffusion und wie wird es installiert?
DreamBooth ist ein Deep-Learning-Generierungsmodell, das generierte Bilder, insbesondere das spezifische Thema, verfeinert. Ursprünglich basiert es auf dem Text-zu-Bild-Modell von Imagen, aber leider verfügt Imagen nicht über die vorab trainierten Gewichte wie Stable Diffusion oder andere KI-Tools. DreamBooth wurde 2022 von Google-Forschern und einigen Kollegen der Boston University weiterentwickelt.
Die Aufgabe des Modells besteht darin, generierte Fotos zu modifizieren und zu verfeinern, es ist aber auch in der Lage, bekannte Motive in jeder Umgebung und Situation wiederzugeben. Da die meisten vorab trainierten Diffusionsmodelle in dieser Kategorie noch verbessert werden müssen, wird DreamBooth das Training für Diffusionsmodelle verstärken. Mit nur fünf Bildern kann die Bildmodifikation mit Plattformen wie Stable Diffusion durchgeführt werden. Hier ist eine kurze Anleitung zur Verwendung von DreamBooth bei Stable Diffusion:
Schritt 1.Zunächst benötigen Sie Trainingsbilder eines Motivs, die Sie auf DreamBooth verwenden können. Stellen Sie sicher, dass vom Motiv Bilder aufgenommen wurden. Ändern Sie die Größe der Bilder auf 512 x 512 Pixel.
Schritt 2.Öffnen Sie DreamBooth und treten Sie ein Instanz-Eingabeaufforderung und Unterrichtsaufforderung. Verarbeiten Sie die Änderungen, indem Sie auf klicken Spiel Klicken Sie auf die Schaltfläche im linken Teil der Benutzeroberfläche.
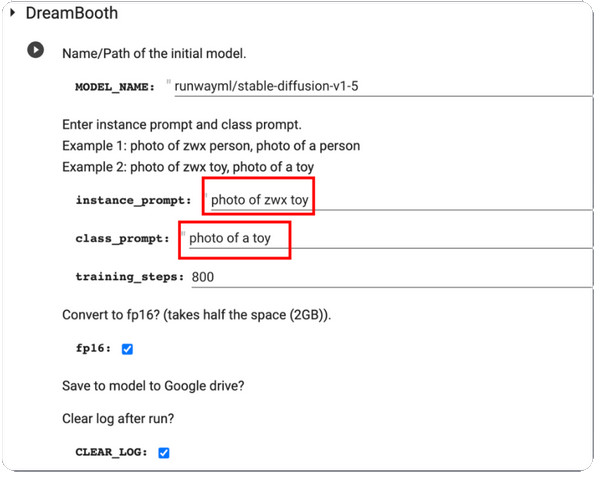
Schritt 3.Wenn Sie fertig sind, testen Sie es und Sie erhalten einige vom Modell generierte Beispiele. Sie können die Modellprüfpunktdatei von Ihrem Google Drive herunterladen und in der GUI installieren.

Teil 4. Was ist die CFG-Skala bei stabiler Diffusion?
Sie finden diesen Wert im Fotogeneratormodell. Und da es wichtig ist, müssen Sie lernen, was es wert ist, Bilder zu optimieren. Mit der Classifier Free Guidance Scale können Benutzer die Nähe des Ergebnisses anhand des Eingabebilds oder der verwendeten Eingabeaufforderungen anpassen. Wenn Sie beispielsweise die CFG-Skalierung auf einen besseren Wert einstellen, wird die Ausgabe dem Eingabebild ähnlicher, es ist jedoch zu erwarten, dass sie verzerrt ist. Andererseits führt eine niedrigere CGF-Skala dazu, dass die Ausgabe weit von der primären Eingabeaufforderung entfernt wird und gleichzeitig eine bessere Qualität erzeugt wird.
Aber wann müssen Sie die CFG-Skala für die stabile Diffusion verwenden? Die Antwort ist einfach: Der KI-Fotogenerator kann nichts erschaffen, von dem er nichts weiß, daher hilft Ihnen die CFG-Skala dabei, mehrere Motive zu verbinden, indem sie deren Wert erhöht. Der einzige Nachteil ist der Aufwand für die Bildqualität, der proportional zu den Eingabeaufforderungen ist. Wenn Sie sich für dieses Tool interessieren, müssen Sie die Kalibrierung der Waage üben, um den optimalen Punkt zu finden.

Teil 5. Was ist Rauschunterdrückung bei stabiler Diffusion?
Diese Methode initiiert einen Prozess, der den Eingabebildern Rauschen hinzufügt. Es ist nur ein Stabiler Diffusions-Upscaler. Es ist ein ausgezeichneter Wert für die stabile Diffusion, da es über Bild-zu-Bild (img2img) oder InPaint erfolgen kann. Die Rauschmenge wird durch Denoise Strength gesteuert, von einem Minimum von 0 bis zu einem Maximum von 1. Wenn Sie den Wert auf 0 setzen, wird das Rauschen auf Null reduziert, wodurch ein dem Eingabebild ähnliches Bild entsteht. Andernfalls ersetzt der Wert 1 die Eingabe durch Rauschen.
Sie können Denoise Strength als praktische Methode verwenden, um die Nähe der Ausgabe zum Einfluss der Eingabebilder zu bestimmen. Ein gutes Beispiel ist eine niedrigere Rauschunterdrückungsstärke, die erzeugte Bilder näher an der Eingabe erscheinen lässt, eine ideale Einstellung für kleinere Änderungen. Andererseits wird eine höhere Rauschunterdrückungsstärke wahrscheinlich die Variation erhöhen und gleichzeitig die Ähnlichkeit der Eingabe- und Ausgabebilder verringern. Daher sind höhere Werte für wesentliche Änderungen hilfreich.

Teil 6. Was ist Clip Skip Stable Diffusion und wie wird es verwendet?
CLIP ist eine Einbettungsebene, die zur Analyse von Texten verwendet wird. Ihre Struktur besteht aus mehreren Ebenen, die für jedes Individuum spezifischer sind als die vorherigen. Beispielsweise kann Ebene 1 „Person“ sein, Ebene 2 „weiblich“ oder „männlich“. Die nächste Ebene ist dann „Elternteil, Vater, Mann, Junge usw.“
Sein Zweck besteht darin, das genaue Textmodell zu erhalten, das die lange Liste von Ebenen stoppt, wodurch schließlich mehr Daten gemischt werden und Sie mehr erhalten, als Sie benötigen. Das beste Beispiel hierfür ist das 1,5-Modell mit 12 Rängen Tiefe. Jede Ebene verfügt über eine Texteinbettung und kann mit anderen Details wie Größe, Farbe usw. gemischt werden. CLIP überspringt die Textraumdimension und gelangt zur genauen Ausgabe. So verwenden Sie es:
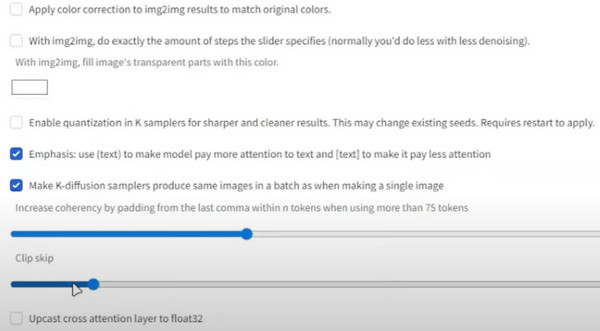
Schritt 1.Gehen Sie vom Stable Diffusion Checkpoint zu den Einstellungen und wählen Sie „Stable Diffusion“ aus.
Schritt 2.Scrollen Sie nach unten und gehen Sie zu „Clip überspringen“. Stellen Sie den gewünschten Wert ein und scrollen Sie dann nach oben, um auf die Schaltfläche „Einstellungen übernehmen“ zu klicken.
Teil 7. Was ist die Geschwindigkeit der stabilen Diffusionserzeugung und wie beschleunigt man sie?
Wenn Sie sich die Geschwindigkeit eines KI-Generators ansehen, werden Sie davon ausgehen, dass es einige Zeit dauern wird, bis Ergebnisse angezeigt werden. Allerdings hat die stabile Diffusion eine Erzeugungsgeschwindigkeit von 10 Sekunden. Dies gilt nur für die allgemeine Nutzung des Online-Tools, bei der Anmeldung zum Primär- oder Standardplan kann die Zeit jedoch dennoch um bis zu vier Sekunden verkürzt werden. Dies ist eine Möglichkeit, die Geschwindigkeit des Modells zu erhöhen, aber die Genauigkeit des Ergebnisses weicht von der Eingabe ab Stabile Diffusionsaufforderungen. Darüber hinaus ist das Tool kostenlos und weist im Vergleich zu den kostenpflichtigen Plänen nur wenige Funktionseinschränkungen auf. Wie können Sie also die Generierungsgeschwindigkeit beschleunigen, ohne dafür zu bezahlen?
Die einzige Voraussetzung für die Beschleunigung ist eine Nvidia-Karte, die der 4000er-, 3000er-, 2000er- und sogar 1000er-Serie angehören kann. Sie können Lovelace, Ampere, Pascal Turing usw. verwenden. Alternativ können Sie eine niedrigere Genauigkeit wie float16 verwenden und weniger Inferenzschritte ausführen.
Bonus-Tipps: Ändern Sie die Größe der stabilen Diffusionsergebnisse
Nachdem Sie sich mit dem KI-Modell vertraut gemacht haben, müssen Sie noch eines wissen: Die Dateigröße ist ein enormer Faktor für Bilder, und aufgrund der größeren Dateigröße können sie Ihren Speicherplatz verschlingen. Aber mit AnyRec Free Image Compressor Online, ist das Komprimieren der Fotos praktisch. Das Online-Tool verfügt über die neueste KI-Technologie, um die Uploads zu optimieren und gleichzeitig die Dateigröße zu reduzieren. Da kleinere Dateien generiert werden, kann der Benutzer mehr Bilder aus dem lokalen Ordner importieren und der Kompressor lädt sie sofort.
- Komprimieren Sie durch stabile Diffusion erzeugte Bilder mit hoher Qualität.
- Auf die komprimierten Bilder darf kein Wasserzeichen angewendet werden.
- Unterstützt Formate wie JPEG, GIF, TIFF, BMP, PNG und mehr.
- Korrigieren Sie verzerrte und verschwommene Pixel automatisch und füllen Sie das Bild mit neuen Pixeln auf.
Teil 8. FAQs zur stabilen Diffusion
-
1. Kann ich Stable Diffusion offline nutzen?
Ja. Das Tool kann ohne Internetverbindung genutzt werden. Dies liegt daran, dass die synthetischen Daten lokal gespeichert werden können, sodass die KI-Modelle so trainiert werden können, dass sie ohne Internetnetzwerk verwendet werden können.
-
2. Welche Nachteile hat der KI-Fotogenerator?
Neben seinen Vorteilen kann das Tool rechenintensiv sein, während es bei der Bearbeitung von Fotos und Videos mit umfangreicheren Daten Zeit kostet. Ein weiterer Grund ist, dass die Qualität von den verwendeten Eingabedaten und Netzwerkparametern abhängt. Daher gibt es keine Garantie dafür, dass Sie ein qualitativ hochwertiges Bild erhalten.
-
3. Benötige ich hochwertige Ausrüstung, wenn ich Stable Diffusion verwende?
Nein. Der Fotogenerator kann ohne die neueste Computerversion verwendet werden. Selbst wenn Sie die neuere Version haben, reicht es aus, den KI-Generator zu verwenden.
-
4. Wo bekomme ich Textaufforderungen?
Stable Diffusion verfügt über einen integrierten Texteingabe-Engineer, der Sie bei der Suche nach Eingabeaufforderungen unterstützt. Geben Sie einfach einen Text ein und klicken Sie auf die Schaltfläche „Suchen“. Die Ergebnisse werden in Sekundenschnelle mit Bildern als Beispielen angezeigt.
-
5. Welche GPU benötige ich zum Ausführen des Online-Tools?
Da es die meisten GPUs unterstützt, können Sie den AI-Bildgenerator mit Nvidia und AMD mit 6 GB ausführen
Abschluss
Dieser Beitrag erklärt Was ist stabile Diffusion? und wie es mit Clip Skip, VAE, DreamBooth, CFG Scale und Denoising Strength funktioniert. Andererseits können Sie AnyRec Free Image Compressor Online verwenden, um die Dateigröße der generierten Bilder zu reduzieren. Die Nutzung ist völlig kostenlos und unbegrenzt!


