Co to jest stabilna dyfuzja i jak zmaksymalizować jej moc
Postęp sztucznej inteligencji przejmuje obecnie kontrolę nad niektórymi programami, które pomogą w generowaniu zdjęć. Możesz zobaczyć narzędzie Stabilna dyfuzja. Ale co to jest stabilna dyfuzja? To narzędzie do generowania obrazu. Jego głównym celem jest generowanie obrazów za pomocą podpowiedzi, a dla ludzi atrakcyjne i zabawne jest wspólne generowanie różnych postaci i elementów. Dowiedz się więcej o tym, czym jest stabilna dyfuzja i dowiedz się, jak działa.
Lista przewodników
Część 1: Co to jest stabilna dyfuzja Część 2: Co to jest stabilna dyfuzja VAE Część 3: Co to jest Dreambooth w stabilnej dyfuzji i jak zainstalować Część 4: Co to jest skala CFG w stabilnej dyfuzji Część 5: Co to jest siła odszumiająca, stabilna dyfuzja Część 6: Co to jest stabilna dyfuzja Clip Skip i jak z niej korzystać Część 7: Co to jest prędkość generowania stabilnej dyfuzji i jak ją przyspieszyć Część 8: Często zadawane pytania dotyczące stabilnej dyfuzjiCzęść 1: Co to jest stabilna dyfuzja
Jest to model głębokiego uczenia się, przekształcający tekst w obraz, tworzący obrazy poprzez wprowadzanie podpowiedzi opisujących główny temat. Na przykład możesz wpisać „kot”, a narzędzie wygeneruje zdjęcie kota. Może jednak jeszcze bardziej podkreślić lub dodać więcej szczegółów podczas wprowadzania złożonych podpowiedzi. Generatywna sieć neuronowa staje się czymś więcej niż narzędziem sztucznej inteligencji, ponieważ jest również uwarunkowana innymi zadaniami, takimi jak odmalowanie, przemalowanie i tłumaczenie obrazu na obraz za pomocą podpowiedzi tekstowych.
Stable Diffusion zostało opracowane i sfinansowane przez Stability AI, ale grupa CompVis na Uniwersytecie Ludwiga Maximiliana w Monachium posiada licencję techniczną na model dyfuzji ukrytej. Co więcej, rozwojem pracowali badacze Patrick Esser i Robin Rombach, zdobywając więcej danych szkoleniowych od organizacji non-profit w Niemczech, które wspierały projekty. Później, w październiku 2022 r., firma zebrała $101 mln USD po wprowadzeniu tej metody w sierpniu 2022 r.
Część 2. Co to jest stabilna dyfuzja VAE
Być może spotkałeś się z tym podczas korzystania z generatora zdjęć AI, a VAE jest pomocne w tym narzędziu. VAE oznacza Variable Auto Encoder, używany do dostrajania dekodera w celu uzyskania lepszych szczegółów. Jest to dodatek do narzędzia AI, ponieważ może pomóc uzyskać wyraźniejsze obrazy i żywe kolory oraz poprawić generowanie dłoni i twarzy.
Oczywiście VAE służy do czegoś więcej niż tylko do stabilnej dyfuzji, ponieważ wszystkie modele mają wbudowane VAE do opracowania szczegółów. Porównanie będzie wynikiem pomiędzy każdym modelem i tym, jak będą wyglądać po skompresowaniu zdjęć. Ponadto istnieją osobne pliki VAE, które można pobrać na swoje urządzenie. Aby wypróbować jeden dekoder, możesz użyć następujących opcji:
- Orangemix/cokolwiek VAE do anime.
- Kl-f8-anime2 dla anime.
- Vae-ft-mse-840000-ema-przycięty pod kątem realizmu lub obrazów.

Część 3. Co to jest Dreambooth w stabilnej dyfuzji i jak zainstalować
DreamBooth to model generowania głębokiego uczenia się, który dostraja wygenerowane obrazy, zwłaszcza konkretny temat. Początkowo opiera się na modelu zamiany tekstu na obraz firmy Imagen, ale niestety Imagen nie posiada wstępnie wytrenowanych wag, takich jak Stable Diffusion czy inne narzędzia AI. Aplikacja DreamBooth została udoskonalona przez badaczy Google i niektórych współpracowników z Uniwersytetu Bostońskiego w 2022 r.
Zadaniem modela jest modyfikowanie i dostrajanie wygenerowanych zdjęć, ale jest on także w stanie renderować znane tematy w dowolnym ustawieniu i sytuacji. Ponieważ większość wstępnie wytrenowanych modeli dyfuzyjnych nadal wymaga udoskonalenia w tej kategorii, DreamBooth przyspieszy szkolenie modeli dyfuzyjnych. Za pomocą zaledwie pięciu obrazów można modyfikować obrazy za pomocą platform takich jak Stable Diffusion. Oto krótka instrukcja korzystania z DreamBooth w trybie Stable Diffusion:
Krok 1.Po pierwsze, musisz mieć obrazy szkoleniowe jednego przedmiotu, które chcesz wykorzystać w DreamBooth. Upewnij się, że obiekt ma zrobione zdjęcia. Kontynuuj zmianę rozmiaru zdjęć na 512x512 pikseli.
Krok 2.Otwórz DreamBooth i wejdź Monit instancji oraz Podpowiedź klasowa. Przetwórz zmiany, klikając przycisk Bawić się przycisk w lewej części interfejsu.
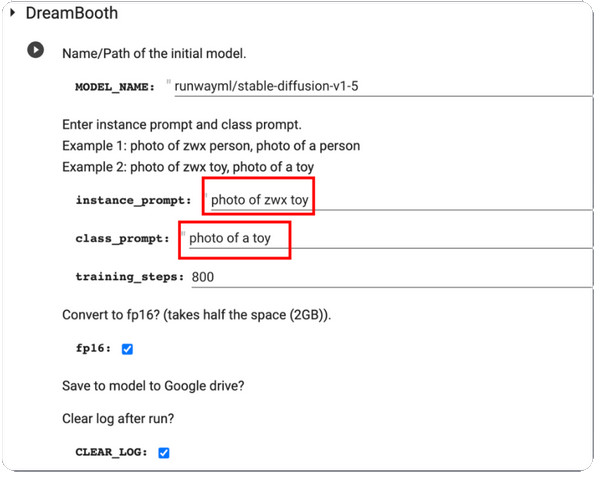
Krok 3.Gdy już to zrobisz, przetestuj go, a otrzymasz kilka próbek wygenerowanych przez model. Możesz pobrać plik punktu kontrolnego modelu z Dysku Google i zainstalować go w GUI.

Część 4. Co to jest skala CFG w stabilnej dyfuzji
Wartość tę można znaleźć w modelu generatora zdjęć. A skoro to istotne, to trzeba dowiedzieć się, co warto optymalizować obrazy. Skala swobodnego naprowadzania klasyfikatora pozwala użytkownikom dostosować stopień zbliżenia wyniku do obrazu wejściowego lub zastosowanych podpowiedzi. Na przykład, gdy ustawisz skalę CFG na lepszą wartość, obraz wyjściowy będzie bardziej podobny do obrazu wejściowego, ale oczekuje się, że będzie zniekształcony. Z drugiej strony niższa skala CGF spowoduje, że dane wyjściowe będą znacznie odbiegać od pierwotnego monitu, generując jednocześnie lepszą jakość.
Ale kiedy trzeba użyć skali CFG na stabilnej dyfuzji? Odpowiedź jest prosta: generator zdjęć AI nie jest w stanie stworzyć czegoś, co nie mieści się w jego wiedzy, dlatego skala CFG pomoże Ci połączyć wiele tematów, podnosząc jej wartość. Jedyną wadą jest koszt jakości obrazu, który jest proporcjonalny do podpowiedzi. Jeśli jesteś zainteresowany tym narzędziem, musisz poćwiczyć kalibrację skali, aby znaleźć idealny punkt.

Część 5. Co to jest siła odszumiająca stabilna dyfuzja
Metoda ta inicjuje proces dodawania szumu do obrazów wejściowych. To jest po prostu Stabilny upscaler dyfuzyjny. Jest to doskonała wartość dla stabilnego rozproszenia, ponieważ może przejść przez obraz do obrazu (img2img) lub InPaint. Poziom szumu jest kontrolowany przez siłę odszumiania, od minimum 0 do maksimum 1. Ustawienie wartości na 0 zredukuje szum do zera, tworząc obraz podobny do obrazu wejściowego. W przeciwnym razie wartość 1 zastąpi wejście szumem.
Można zastosować siłę usuwania szumu jako praktyczną metodę określania zgodności sygnału wyjściowego z wpływem obrazów wejściowych. Świetnym przykładem jest niższa siła odszumiania, która sprawia, że wygenerowane obrazy wyglądają bliżej sygnału wejściowego, co jest idealnym ustawieniem do drobnych modyfikacji. Z drugiej strony, wyższa siła odszumiania prawdopodobnie zwiększy zmienność, jednocześnie zmniejszając podobieństwo obrazów wejściowych i wyjściowych. Dlatego wyższe wartości są pomocne w przypadku znaczących modyfikacji.

Część 6. Co to jest stabilna dyfuzja Clip Skip i jak z niej korzystać
CLIP jest znany jako warstwa osadzająca używana do analizy tekstów. Jego struktura składa się z warstw, które z osobna są bardziej specyficzne niż poprzednie. Na przykład warstwa 1 może być „Osoba”, a warstwa 2 będzie „kobieta” lub „mężczyzna”. Następnie następną warstwą będą „rodzic, ojciec, mężczyzna, chłopiec itd.”
Jego celem jest uzyskanie precyzyjnego modelu tekstowego, który zatrzymuje długą listę warstw, ostatecznie mieszając więcej danych i dając więcej, niż potrzebujesz. Najlepszym tego przykładem jest model 1,5 z głębokością 12 stopni. Każda warstwa zawiera tekst i można ją mieszać z innymi szczegółami, takimi jak rozmiar, kolor itp. CLIP pomija wymiar przestrzeni tekstowej i przechodzi do dokładnego wyniku. Oto jak z niego korzystać:
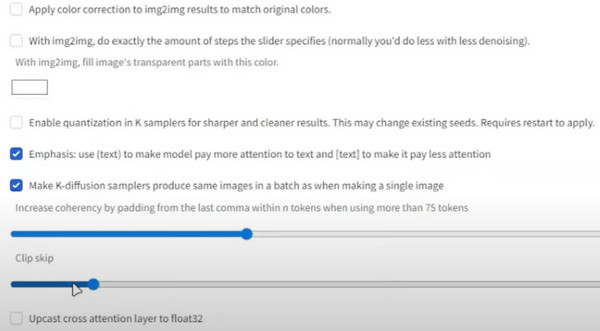
Krok 1.Z punktu kontrolnego stabilnej dyfuzji przejdź do ustawień i wybierz „Stabilna dyfuzja”.
Krok 2.Przewiń w dół i przejdź do „Pomiń klip”. Ustaw żądaną wartość, a następnie przewiń w górę i kliknij przycisk „Zastosuj ustawienia”.
Część 7. Co to jest prędkość generowania stabilnej dyfuzji i jak ją przyspieszyć
Patrząc na szybkość generatora AI, można się spodziewać, że wyświetlenie wyników zajmie trochę czasu. Jednak stabilna dyfuzja ma prędkość generowania 10 sekund. Dotyczy to tylko ogólnego korzystania z narzędzia online, ale w przypadku subskrypcji planu podstawowego lub standardowego czas może jeszcze skrócić się do czterech sekund. Jest to jeden ze sposobów zwiększenia szybkości modelu, ale dokładność wyniku odbiega od danych wejściowych Monity o stabilnym rozproszeniu. Co więcej, narzędzie jest bezpłatne i ma tylko kilka ograniczeń funkcji wynikających z planów cenowych. Jak więc przyspieszyć prędkość generowania, nie płacąc?
Jedynym wymaganiem do przyspieszenia jest karta Nvidia, która może należeć do serii 4000, 3000, 2000, a nawet 1000. Możesz użyć Lovelace, Ampere, Pascal Turing itp. Alternatywnie użyj niższej precyzji, takiej jak float16 i wykonaj mniej kroków wnioskowania.
Dodatkowe wskazówki: Zmień rozmiar stabilnych wyników dyfuzji
Po zapoznaniu się z modelem sztucznej inteligencji musisz wiedzieć jeszcze jedną rzecz: rozmiar pliku ma ogromne znaczenie w przypadku obrazów i mogą one pochłonąć Twoją przestrzeń dyskową ze względu na większe rozmiary plików. Ale z Darmowy kompresor obrazu AnyRec online, kompresowanie zdjęć będzie wygodne. Narzędzie online wykorzystuje najnowszą technologię sztucznej inteligencji, która pomaga zoptymalizować przesyłanie przy jednoczesnym zmniejszeniu rozmiaru pliku. Generując mniejsze pliki, użytkownik może zaimportować więcej obrazów z folderu lokalnego, a kompresor natychmiast je załaduje.
- Kompresuj obrazy generowane przez stabilne rozproszenie z zachowaniem jakości.
- Do skompresowanych obrazów nie należy stosować znaku wodnego.
- Obsługiwane formaty, takie jak JPEG, GIF, TIFF, BMP, PNG i inne.
- Automatycznie napraw zniekształcone, rozmyte i uzupełnij nowe piksele obrazu.
Część 8. Często zadawane pytania dotyczące stabilnej dyfuzji
-
1. Czy mogę korzystać ze Stable Diffusion w trybie offline?
Tak. z narzędzia można korzystać bez połączenia z Internetem. Dzieje się tak dlatego, że może przechowywać syntetyczne dane lokalnie, umożliwiając szkolenie modeli sztucznej inteligencji, aby mogły z nich korzystać bez sieci internetowej.
-
2. Jakie są wady generatora zdjęć AI?
Oprócz swoich zalet narzędzie to może wymagać dużej mocy obliczeniowej, a jednocześnie zajmuje dużo czasu w przypadku zdjęć i filmów zawierających bardziej rozbudowane dane. Innym jest to, że jakość zależy od danych wejściowych i zastosowanych parametrów sieci. Oznacza to, że nie ma gwarancji, że otrzymasz obraz wysokiej jakości.
-
3. Czy do korzystania ze Stable Diffusion potrzebny jest sprzęt najwyższej klasy?
Nie. Z generatora zdjęć można korzystać bez najnowszej wersji komputera. Nawet jeśli posiadasz nowszą wersję, wystarczy skorzystać z generatora AI.
-
4. Gdzie uzyskać podpowiedzi tekstowe?
Stable Diffusion ma wbudowany moduł podpowiedzi tekstowych, który pomaga w wyszukiwaniu podpowiedzi. Wystarczy wpisać tekst i kliknąć przycisk Szukaj. Wyniki pojawią się w ciągu kilku sekund, a obrazy będą próbkami.
-
5. Jakiego procesora graficznego potrzebuję, aby uruchomić narzędzie online?
Ponieważ obsługuje większość procesorów graficznych, możesz uruchomić generator obrazu AI z Nvidią i AMD przy 6 GB
Wniosek
Ten post wyjaśnia co to jest stabilna dyfuzja oraz jak to działa z Clip Skip, VAE, DreamBooth, CFG Scale i Denoising Strength. Z drugiej strony możesz użyć AnyRec Free Image Compressor Online, aby zmniejszyć rozmiar plików generowanych zdjęć. Korzystanie z niego jest całkowicie bezpłatne i nieograniczone!