什麼是穩定擴散以及如何最大化其威力
人工智慧的進步現在正在接管一些有助於生成圖片的程式。您可能會看到穩定擴散工具。但 什麼是穩定擴散?這是一個圖像生成工具。它的主要目的是根據提示生成圖片,人們發現一起生成各種角色和元素很有吸引力且有趣。詳細了解什麼是穩定擴散並了解其工作原理。
指南列表
第 1 部分:什麼是穩定擴散 第 2 部分:什麼是 VAE 穩定擴散 第 3 部分:Stable Diffusion 上的 Dreambooth 是什麼以及如何安裝 第 4 部分:什麼是穩定擴散中的 CFG 尺度 第五部分:什麼是去雜訊強度穩定擴散 第 6 部分:什麼是 Clip Skip 穩定擴散以及如何使用 第七部分:什麼是穩定擴散生成速度以及如何加速 第 8 部分:有關穩定擴散的常見問題解答第 1 部分:什麼是穩定擴散
它是一種深度學習的文本到圖像模型,透過輸入描述主要主題的提示來創建圖片。例如,您可以輸入“貓”,該工具將產生一張貓的圖片。然而,當您輸入複雜的提示時,它可以進一步強調或添加更多細節。生成神經網路不僅僅是一個人工智慧工具,因為它還受其他任務的限制,例如透過文字提示進行外畫、修復和圖像到圖像的翻譯。
Stable Diffusion 由 Stability AI 開發和資助,但慕尼黑路德維希馬克西米利安大學的 CompVis 小組擁有潛在擴散模型的技術許可。此外,該開發由研究人員 Patrick Esser 和 Robin Rombach 領導,他們從作為專案支持者的德國非營利組織獲得了更多培訓數據。 2022 年 10 月晚些時候,該公司在 2022 年 8 月首次推出後籌集了 1.01 億美元。
第 2 部分. 什麼是 VAE 穩定擴散
您在使用AI照片產生器時可能遇到過這種情況,VAE對該工具很有幫助。 VAE 代表可變自動編碼器,用於微調解碼器以繪製更好的細節。它是人工智慧工具的補充,因為它可以幫助獲得更清晰的圖像和鮮豔的色彩,並改善手和臉的生成。
當然,VAE 不僅僅用於穩定擴散,因為所有模型都有內建的 VAE 來計算細節。比較將是每個模型之間的結果以及壓縮圖片時它們的結果。此外,您也可以將單獨的 VAE 檔案下載到您的裝置上。要嘗試解碼器,您可以使用以下命令:
- Orangemix/任何動漫 VAE。
- KL-f8-anime2 用於動漫。
- Vae-ft-mse-840000-ema-為寫實或繪畫修剪。

第 3 部分. 什麼是 Dreambooth on Stable Diffusion 以及如何安裝
DreamBooth 是一種深度學習生成模型,可以對生成的圖片,尤其是特定主題進行微調。最初,它是基於 Imagen 的文本到圖像模型,但不幸的是,Imagen 沒有像 Stable Diffusion 或其他 AI 工具那樣預先訓練的權重。 DreamBooth 由 Google 研究人員和波士頓大學的一些同事於 2022 年進一步開發。
該模型的工作是修改和微調生成的照片,但它也能夠在任何設定和情況下渲染熟悉的主題。由於大多數預先訓練的擴散模型在該類別中仍需要改進,DreamBooth將加強對擴散模型的訓練。只需五張影像,就可以使用穩定擴散等平台來完成影像修改。以下是如何在穩定擴散上使用 DreamBooth 的簡短說明:
步驟1。首先,您必須擁有要在 DreamBooth 上使用的一個主題的訓練圖像。確保拍攝對像已被拍攝。繼續將圖片大小調整為 512x512 像素。
第2步。打開DreamBooth並進入 實例提示 和 課堂提示。透過點擊處理更改 玩 介面左側的按鈕。
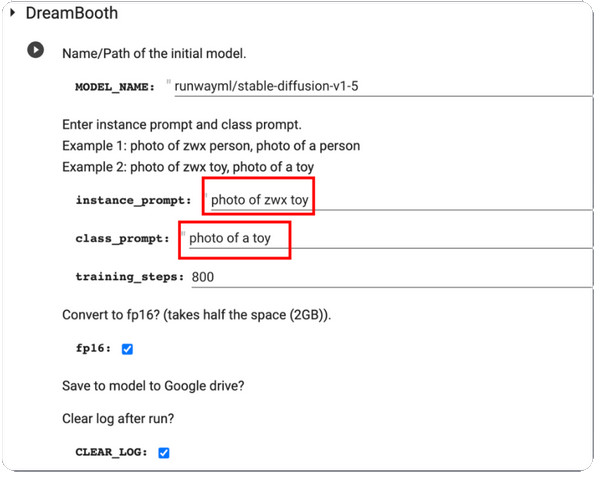
第 3 步。完成後,對其進行測試,您將收到模型產生的一些樣本。您可以從 Google Drive 下載模型檢查點檔案並將其安裝在 GUI 中。

第 4 部分:什麼是穩定擴散中的 CFG 尺度
您可以在照片產生器模型中找到此值集。既然它是必要的,那麼你就必須了解什麼是值得優化影像的。分類器自由指導量表允許使用者調整結果與輸入影像或使用的提示的接近程度。例如,當您將 CFG 比例調整為更出色的值時,輸出將與輸入影像更相似,但預計會失真。另一方面,較低的 CGF 比例將使輸出遠離主要提示,同時產生更好的品質。
但是什麼時候需要在穩定擴散上使用 CFG 比例呢?答案很簡單:AI 照片產生器無法創建超出其知識範圍的東西,因此 CFG 量表將透過調高其值來幫助您連接多個主題。唯一的缺點是影像品質的代價,這與提示成正比。如果對這個工具有興趣,您必須練習校準秤以找到最佳位置。

第 5 部分. 什麼是去噪強度穩定擴散
此方法啟動一個向輸入影像添加雜訊的過程。它只是一個 穩定的擴散放大器。它對於穩定擴散具有極好的價值,因為它可以通過圖像到圖像(img2img)或InPaint。噪聲量由「降噪強度」控制,從最小值 0 到最大值 1。將該值設為 0 會將雜訊減少到無噪聲,從而產生與輸入影像相似的影像。否則,值 1 會將輸入替換為雜訊。
您可以使用降噪強度作為實用方法來確定輸出與輸入影像影響的接近程度。一個很好的例子是較低的去噪強度,使產生的影像看起來更接近輸入,這是進行細微修改的理想設定。另一方面,較高的去噪強度可能會增加變化,同時降低輸入和輸出影像的相似性。因此,較高的值有助於進行重大修改。

第 6 部分. 什麼是 Clip Skip 穩定擴散以及如何使用
CLIP 被稱為用於分析文字的嵌入層。它的結構是由層組成的,每個個體都比前一層更具體。例如,第 1 層可以是“人”,第 2 層可以是“女性”或“男性”。然後,下一層將是「父母、父親、男人、男孩等」。
其目的是獲得精確的文字模型,從而停止一長串圖層,最終混合更多資料並為您提供超出您需要的資料。最好的例子是 1.5 模型,其深度為 12 個。每層都有文字嵌入,並且可以與其他細節混合,例如大小、顏色等。CLIP 跳過文字空間維度並獲得精確的輸出。使用方法如下:
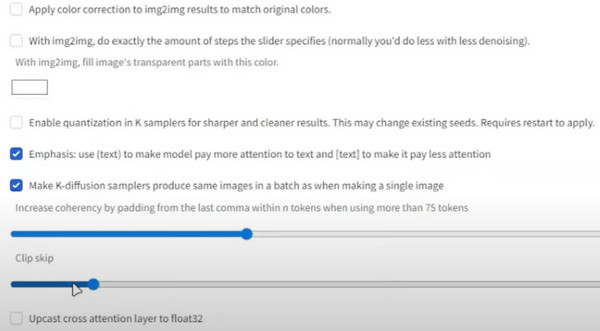
步驟1。從穩定擴散檢查點,轉到設定並選擇“穩定擴散”。
第2步。向下捲動並轉到“剪輯跳過”。請將其設定為所需的值,然後向上捲動以按一下「套用設定」按鈕。
第七部分 什麼是穩定擴散生成速度以及如何加速
當您查看人工智慧產生器的速度時,您會預期需要一些時間才能顯示結果。然而,穩定擴散的生成速度為10秒。這僅適用於線上工具的一般使用,但是當訂閱主要或標準計劃時,時間仍然可以縮短最多四秒。這是加快模型速度的一種方法,但結果的準確性偏離輸入 穩定擴散提示。此外,該工具是免費的,只有定價計劃中的一些功能限制。那麼,如何在不付費的情況下加快生成速度呢?
加速的唯一要求是 Nvidia 卡,可以是 4000、3000、2000 甚至 1000 系列。您可以使用 Lovelace、Ampere、Pascal Turing 等。作為替代方案,請使用 float16 等較低精度並運行更少的推理步驟。
額外提示:更改穩定擴散結果大小
在了解了人工智慧模型之後,您還必須了解一件事:檔案大小是圖像的一個重要因素,並且由於檔案大小較大,它們可能會佔用您的儲存空間。但與 AnyRec 免費在線圖像壓縮器,壓縮照片會很方便。該線上工具具有最新的人工智慧技術,可以幫助優化上傳,同時減少檔案大小。由於它產生的檔案較小,因此使用者可以從本機資料夾匯入更多圖像,壓縮器將立即載入它們。
- 高品質壓縮穩定擴散產生的影像。
- 壓縮影像上沒有套用浮水印。
- 支援 JPEG、GIF、TIFF、BMP、PNG 等格式。
- 自動修復影像的扭曲、模糊和填滿新像素。
第 8 部分. 有關穩定擴散的常見問題解答
-
1.我可以離線使用穩定擴散嗎?
是的。該工具無需網路連線即可使用。這是因為它可以在本地儲存合成數據,使人工智慧模型能夠在沒有網路的情況下進行訓練。
-
2.AI照片產生器有哪些缺點?
除了其優點之外,該工具可能需要大量計算,而在處理具有更廣泛數據的照片和影片時會消耗時間。另一種是品質取決於輸入資料和使用的網路參數。這意味著無法保證您將獲得高品質的圖像。
-
3.使用穩定擴散需要高端裝備嗎?
不需要。照片產生器無需最新的電腦版本即可使用。即使你有更高版本,使用AI生成器也足夠了。
-
4. 從哪裡取得文字提示?
Stable Diffusion 內建了文字提示工程師,可以幫助您搜尋提示。只需輸入文字並點擊“搜尋”按鈕即可。結果將在幾秒鐘內出現,並以圖像作為樣本。
-
5. 運行線上工具需要什麼 GPU?
由於它支援大多數 GPU,因此您可以使用 Nvidia 和 AMD 以 6GB 運行 AI 圖像生成器
結論
這篇文章解釋了 什麼是穩定擴散 以及它如何與 Clip Skip、VAE、DreamBooth、CFG Scale 和 Denoising Strength 搭配使用。另一方面,您可以使用AnyRec免費圖像壓縮器在線來減少生成圖片的檔案大小。它完全免費且無限制使用!